今天趁着群友尝试部署透明代理的机会,彻底学习了一遍 TProxy 的原理。网上原理这方面的内容比较少,可能是因为太过简单了吧,但对我来说还是太神必了
ToC
何为 TProxy?
TProxy 对于使用过透明代理的人来说应该相对比较熟悉了吧,至少名字还是听到过的
所有的 TProxy 介绍文章都会告诉我们,TProxy 不会修改报文头,但却可以将报文转发。正如官方文档所言:
It redirects the packet to a local socket without changing the packet header in any way.
它会将数据包重定向到一个本地的 socket 上,而不会以任何形式修改包的头部。
那它究竟是怎么工作的呢?
TProxy 原理
出于方便IPv4 的情况,IPv6 基本是同理的,这里就不重复了。
这里我们使用的是 Linux 内核版本 4.16.1 的 /net/netfilter/xt_TPROXY.c [2]。
入口
首先我们来看入口:
static struct xt_target tproxy_tg_reg[] __read_mostly = { { .name = "TPROXY", .family = NFPROTO_IPV4, .table = "mangle", .target = tproxy_tg4_v0, .revision = 0, .targetsize = sizeof(struct xt_tproxy_target_info), .checkentry = tproxy_tg4_check, .hooks = 1 << NF_INET_PRE_ROUTING, .me = THIS_MODULE, }, { .name = "TPROXY", .family = NFPROTO_IPV4, .table = "mangle", .target = tproxy_tg4_v1, .revision = 1, .targetsize = sizeof(struct xt_tproxy_target_info_v1), .checkentry = tproxy_tg4_check, .hooks = 1 << NF_INET_PRE_ROUTING, .me = THIS_MODULE, },#ifdef XT_TPROXY_HAVE_IPV6 { .name = "TPROXY", .family = NFPROTO_IPV6, .table = "mangle", .target = tproxy_tg6_v1, .revision = 1, .targetsize = sizeof(struct xt_tproxy_target_info_v1), .checkentry = tproxy_tg6_check, .hooks = 1 << NF_INET_PRE_ROUTING, .me = THIS_MODULE, },#endif
};
static int __init tproxy_tg_init(void){ return xt_register_targets(tproxy_tg_reg, ARRAY_SIZE(tproxy_tg_reg));}
static void __exit tproxy_tg_exit(void){ xt_unregister_targets(tproxy_tg_reg, ARRAY_SIZE(tproxy_tg_reg));}
module_init(tproxy_tg_init);module_exit(tproxy_tg_exit);MODULE_LICENSE("GPL");MODULE_AUTHOR("Balazs Scheidler, Krisztian Kovacs");MODULE_DESCRIPTION("Netfilter transparent proxy (TPROXY) target module.");MODULE_ALIAS("ipt_TPROXY");MODULE_ALIAS("ip6t_TPROXY");从这里我们可以了解到,TProxy 模块工作在 mangle 表上,且工作(配置成功)前需要经过 tproxy_tg4_check 的检查;成功配置后,则通过 tproxy_tg4_v0 或 tproxy_tg4_v1 运作,这里我们自然是看 v1。
tproxy_tg4_check
static int tproxy_tg4_check(const struct xt_tgchk_param *par){ const struct ipt_ip *i = par->entryinfo; int err;
err = nf_defrag_ipv4_enable(par->net); if (err) return err;
if ((i->proto == IPPROTO_TCP || i->proto == IPPROTO_UDP) && !(i->invflags & IPT_INV_PROTO)) return 0;
pr_info_ratelimited("Can be used only with -p tcp or -p udp\n"); return -EINVAL;}我们看到,想要使用 TProxy 有两个前提条件:
- 启用了
nf_defrag_ipv4。 - 协议为
TCP或UDP。
tproxy_tg4_v1
static unsigned inttproxy_tg4_v1(struct sk_buff *skb, const struct xt_action_param *par){ const struct xt_tproxy_target_info_v1 *tgi = par->targinfo;
return tproxy_tg4(xt_net(par), skb, tgi->laddr.ip, tgi->lport, tgi->mark_mask, tgi->mark_value);}可以看到,这里我们本质执行的是 tproxy_tg4,传递的参数有:
xt_net(par):即net。skb:即socket_buffer,是这一步中需要处理的本体。laddr.ip、lport:配置中设置的ip和port,对应的是--on-ip和--on-port。mask_mask、mask_value:对应--tproxy-mark的value/mask。
tproxy_tg4
static unsigned inttproxy_tg4(struct net *net, struct sk_buff *skb, __be32 laddr, __be16 lport, u_int32_t mark_mask, u_int32_t mark_value){ const struct iphdr *iph = ip_hdr(skb); struct udphdr _hdr, *hp; struct sock *sk;
hp = skb_header_pointer(skb, ip_hdrlen(skb), sizeof(_hdr), &_hdr); if (hp == NULL) return NF_DROP;
/* check if there's an ongoing connection on the packet * addresses, this happens if the redirect already happened * and the current packet belongs to an already established * connection */ sk = nf_tproxy_get_sock_v4(net, skb, hp, iph->protocol, iph->saddr, iph->daddr, hp->source, hp->dest, skb->dev, NFT_LOOKUP_ESTABLISHED);
laddr = tproxy_laddr4(skb, laddr, iph->daddr); if (!lport) lport = hp->dest;
/* UDP has no TCP_TIME_WAIT state, so we never enter here */ if (sk && sk->sk_state == TCP_TIME_WAIT) /* reopening a TIME_WAIT connection needs special handling */ sk = tproxy_handle_time_wait4(net, skb, laddr, lport, sk); else if (!sk) /* no, there's no established connection, check if * there's a listener on the redirected addr/port */ sk = nf_tproxy_get_sock_v4(net, skb, hp, iph->protocol, iph->saddr, laddr, hp->source, lport, skb->dev, NFT_LOOKUP_LISTENER);
/* NOTE: assign_sock consumes our sk reference */ if (sk && tproxy_sk_is_transparent(sk)) { /* This should be in a separate target, but we don't do multiple targets on the same rule yet */ skb->mark = (skb->mark & ~mark_mask) ^ mark_value;
pr_debug("redirecting: proto %hhu %pI4:%hu -> %pI4:%hu, mark: %x\n", iph->protocol, &iph->daddr, ntohs(hp->dest), &laddr, ntohs(lport), skb->mark);
nf_tproxy_assign_sock(skb, sk); return NF_ACCEPT; }
pr_debug("no socket, dropping: proto %hhu %pI4:%hu -> %pI4:%hu, mark: %x\n", iph->protocol, &iph->saddr, ntohs(hp->source), &iph->daddr, ntohs(hp->dest), skb->mark); return NF_DROP;}从头看起。307 行定义并获取了 IP 报头;308 行定义了 UDP 报头,并且在 311 行获取了这个报头的内容(指针);309 行定义了 socket 指针。这几步是初始的定义过程。
UDP 头部?
这里产生了一个疑问:为什么第 309 行是 udphdr 呢?实际上,通过观察,我们会发现:TCP 报头和 UDP 报头的前 4 个字节的意义是一致的,均代表源端口和目标端口:


而由于后续的需要,我们要用到这两个端口,因此在这里我们尝试获取 UDP 报文的头部。于是 312-313 行:当获取出现错误时丢弃报文的行为意图也就非常清楚了。
下面我们跳着看,先看 324-326 行。这三行调用了 tproxy_laddr4 函数。
tproxy_laddr4
static inline __be32tproxy_laddr4(struct sk_buff *skb, __be32 user_laddr, __be32 daddr){ struct in_device *indev; __be32 laddr;
if (user_laddr) return user_laddr;
laddr = 0; indev = __in_dev_get_rcu(skb->dev); for_primary_ifa(indev) { laddr = ifa->ifa_local; break; } endfor_ifa(indev);
return laddr ? laddr : daddr;}这个函数是用来获取 laddr 的。函数逻辑非常明确:当存在 user_laddr,从配置上来说就是用户定义了 --to-ip 时,使用用户定义的 ip;否则就尝试获取本地 IP(即 ifa_local);当未获取到时最后 fallback 到原本的目标地址。
在获得了 laddr 之后,我们还需要获得一个端口。因此,当未设置端口时,我们直接使用了从报文头部获得的目标端口。
回到 319-322 行。这里,包括下面的 329-331 行,处理的是当前已经建立但却没有遵循 TProxy 配置的连接。这种情况最常见的出现情形是在这条规则刚被添加之后,此时需要处理现有的连接。这里我们先跳过 nf_tproxy_get_sock_v4,只要知道它是用来获取 sk 的就够了。
如果我们得到了 sk,那我们需要处理的首先就是 TCP 的 TIME_WAIT 状态。对于 TCP TIME_WAIT 的解释可以参考[3]。由于在这种状态下,客户端可能会通过 SYN 与服务端重新建立连接,因此我们应该尝试把连接交给 TProxy 处理。我们来看看 TProxy 是怎么处理 TIME_WAIT 的:
tproxy_handle_time_wait4
/** * tproxy_handle_time_wait4 - handle IPv4 TCP TIME_WAIT reopen redirections * @skb: The skb being processed. * @laddr: IPv4 address to redirect to or zero. * @lport: TCP port to redirect to or zero. * @sk: The TIME_WAIT TCP socket found by the lookup. * * We have to handle SYN packets arriving to TIME_WAIT sockets * differently: instead of reopening the connection we should rather * redirect the new connection to the proxy if there's a listener * socket present. * * tproxy_handle_time_wait4() consumes the socket reference passed in. * * Returns the listener socket if there's one, the TIME_WAIT socket if * no such listener is found, or NULL if the TCP header is incomplete. */static struct sock *tproxy_handle_time_wait4(struct net *net, struct sk_buff *skb, __be32 laddr, __be16 lport, struct sock *sk){ const struct iphdr *iph = ip_hdr(skb); struct tcphdr _hdr, *hp;
hp = skb_header_pointer(skb, ip_hdrlen(skb), sizeof(_hdr), &_hdr); if (hp == NULL) { inet_twsk_put(inet_twsk(sk)); return NULL; }
if (hp->syn && !hp->rst && !hp->ack && !hp->fin) { /* SYN to a TIME_WAIT socket, we'd rather redirect it * to a listener socket if there's one */ struct sock *sk2;
sk2 = nf_tproxy_get_sock_v4(net, skb, hp, iph->protocol, iph->saddr, laddr ? laddr : iph->daddr, hp->source, lport ? lport : hp->dest, skb->dev, NFT_LOOKUP_LISTENER); if (sk2) { inet_twsk_deschedule_put(inet_twsk(sk)); sk = sk2; } }
return sk;}顶部的注释清晰地说明了函数的用途。来看代码,267-274 行获取了 IP 头部和 TCP 头部,而 276-289 行则对 SYN 进行了特殊处理:它尝试去获得了当前监听目标 IP 和目标端口的 socket,当存在时,则将 sk 替换。
处理完 TCP_TIME_WAIT,接下来就是不存在 sk 的情况了。如 332-338 行所写,这种情况下的连接只需要尝试获得是否有监听目标 IP:端口的存在就可以了。
到这里为止,所有尝试获取 sk 的行为都已经结束了。也就是说,接下来就是魔法的时刻了。我们来看 341-351 行:当 sk 存在且 tproxy_sk_is_transparent 判断成功时,我们设置当前 skb 的 mark,并且通过 nf_tproxy_assign_sock 设置 skb 的 sk,最后返回 ACCEPT。
至此,TProxy 的处理结束。
tproxy_sk_is_transparent
这里我们来看一下上面
static bool tproxy_sk_is_transparent(struct sock *sk){ switch (sk->sk_state) { case TCP_TIME_WAIT: if (inet_twsk(sk)->tw_transparent) return true; break; case TCP_NEW_SYN_RECV: if (inet_rsk(inet_reqsk(sk))->no_srccheck) return true; break; default: if (inet_sk(sk)->transparent) return true; }
sock_gen_put(sk); return false;}这里限定了需要处理的 sk 状态类型:
TCP_TIME_WAIT状态下 启用了tw_transparent的(这里的tw其实就是time wait的缩写。TCP_NEW_SYN_RECV状态下启用了no_srccheck的。transparent的。
其实,这里检查的是 sk 是否支持透明代理。正如官方文档所描述:
Because of certain restrictions in the IPv4 routing output code you’ll have to modify your application to allow it to send datagrams from non-local IP addresses. All you have to do is enable the (SOL_IP, IP_TRANSPARENT) socket option before calling bind:
由于 IPv4 路由输出代码的限制(译注:其实 IPv6 也有),你必须修改程序使其能够从非本地的 IP 地址发送数据报。你要做的就是在 bind 之前启用 (SOL_IP, IP_TRANSPARENT) 的 socket 选项。
nf_tproxy_assign_sock
/* assign a socket to the skb -- consumes sk */static voidnf_tproxy_assign_sock(struct sk_buff *skb, struct sock *sk){ skb_orphan(skb); skb->sk = sk; skb->destructor = sock_edemux;}这里总共做了三件事情:
- 将原本
skb的sk销毁。 - 将新的
sk赋给skb。 - 将
skb的destructor设置为sock_edemux。
nf_tproxy_get_sock_v4
/* * This is used when the user wants to intercept a connection matching * an explicit iptables rule. In this case the sockets are assumed * matching in preference order: * * - match: if there's a fully established connection matching the * _packet_ tuple, it is returned, assuming the redirection * already took place and we process a packet belonging to an * established connection * * - match: if there's a listening socket matching the redirection * (e.g. on-port & on-ip of the connection), it is returned, * regardless if it was bound to 0.0.0.0 or an explicit * address. The reasoning is that if there's an explicit rule, it * does not really matter if the listener is bound to an interface * or to 0. The user already stated that he wants redirection * (since he added the rule). * * Please note that there's an overlap between what a TPROXY target * and a socket match will match. Normally if you have both rules the * "socket" match will be the first one, effectively all packets * belonging to established connections going through that one. */static inline struct sock *nf_tproxy_get_sock_v4(struct net *net, struct sk_buff *skb, void *hp, const u8 protocol, const __be32 saddr, const __be32 daddr, const __be16 sport, const __be16 dport, const struct net_device *in, const enum nf_tproxy_lookup_t lookup_type){ struct sock *sk; struct tcphdr *tcph;
switch (protocol) { case IPPROTO_TCP: switch (lookup_type) { case NFT_LOOKUP_LISTENER: tcph = hp; sk = inet_lookup_listener(net, &tcp_hashinfo, skb, ip_hdrlen(skb) + __tcp_hdrlen(tcph), saddr, sport, daddr, dport, in->ifindex, 0);
if (sk && !refcount_inc_not_zero(&sk->sk_refcnt)) sk = NULL; /* NOTE: we return listeners even if bound to * 0.0.0.0, those are filtered out in * xt_socket, since xt_TPROXY needs 0 bound * listeners too */ break; case NFT_LOOKUP_ESTABLISHED: sk = inet_lookup_established(net, &tcp_hashinfo, saddr, sport, daddr, dport, in->ifindex); break; default: BUG(); } break; case IPPROTO_UDP: sk = udp4_lib_lookup(net, saddr, sport, daddr, dport, in->ifindex); if (sk) { int connected = (sk->sk_state == TCP_ESTABLISHED); int wildcard = (inet_sk(sk)->inet_rcv_saddr == 0);
/* NOTE: we return listeners even if bound to * 0.0.0.0, those are filtered out in * xt_socket, since xt_TPROXY needs 0 bound * listeners too */ if ((lookup_type == NFT_LOOKUP_ESTABLISHED && (!connected || wildcard)) || (lookup_type == NFT_LOOKUP_LISTENER && connected)) { sock_put(sk); sk = NULL; } } break; default: WARN_ON(1); sk = NULL; }
pr_debug("tproxy socket lookup: proto %u %08x:%u -> %08x:%u, lookup type: %d, sock %p\n", protocol, ntohl(saddr), ntohs(sport), ntohl(daddr), ntohs(dport), lookup_type, sk);
return sk;}这就是获得 sk 的函数了。它根据协议的不同又分为 TCP 和 UDP 两类。对于 TCP,没有什么特殊的地方,看函数名基本都能顾名思义,这里略过;对于 UDP,我们同样是首先先 lookup,然后根据 lookup_type 的情况解除对 sk 的引用。这里的 sock_put 就是减少引用数量的,同时当无引用时,会直接 sk_free(sk)。
目标地址/端口的来源
读完上面的内容,相信这个问题也就迎刃而解了。正是由于 TProxy 并没有修改报文内容,而只是将报文的 socket 给偷梁换柱了,因此报文经过的也正是正常的 Linux 处理流程。因此,通过系统调用就可以获得原报文的目标地址和目标端口了。
经典的策略路由
要实现透明代理,离不开 iproute 的配合。下面就是最经典的策略路由的实现[5]:
iptables -t mangle -I PREROUTING -p udp --dport 5301 -j MARK --set-mark 1# 等价# nft insert rule ip mangle PREROUTING udp dport 5301 counter meta mark set 0x1
ip rule add fwmark 1 lookup 100ip route add local 0.0.0.0/0 dev lo table 100我们一行一行看:第一(至三)行添加了一条 iptables 规则,负责将目标端口为 5301 的 UDP 流量打上 mark 为 1;第五行告诉 iproute 对于 fwmark=1 的流量查表 100;而最后一行则声明:所有的 IPv4 地址在表 100 中均为 local。
对于 TProxy 来说,道理也是一样的,只不过有一件事情比较特殊:TProxy 的目标地址不是本机。也就是说,如果不设置 mark,那么这份报文就会被转发(被 FORWARD 链处理)而不是被 INPUT 链处理[6]。为了实现透明代理,这份报文必须被本机处理,因此 TProxy 就必须设置 --tproxy-mask。而为了让报文不被转发,这里就需要辅以上面 2-3 行的策略路由了。
完整的 TProxy 实现命令如下:
# 策略路由ip rule add fwmark 1 lookup 100ip route add local 0.0.0.0/0 dev lo table 100
# TProxyiptables -t mangle -I PREROUTING -p udp --dport 53 -j TPROXY --on-port 1090 --tproxy-mark 1TProxy 网关透明代理
我们知道,网关发出的流量走的是 OUTPUT 链,之后的步骤就没有 PREROUTING 的位置了。那是不是就意味着网关自身就一定无法实现透明代理了呢?答案是否定的。
还是回到刚才的策略路由。现在我们已经有了这样一个将所有 IPv4 地址都当作本机的策略路由,那我们只要让我们的流量经过策略路由选择之后再回到网关,是不是就相当于从 NETWORK 收到一份新的报文呢?
这里我们引用另外一张图[7]:
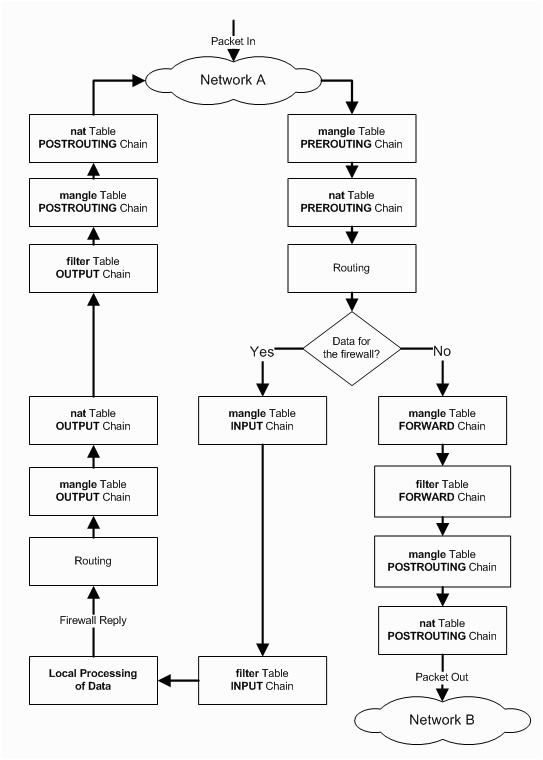
我们来观察这张图。Local Processing of Data 先经过第一次路由选择,再流经 mangle 表 OUTPUT 链、nat 表 OUTPUT 链等等,进行第二次路由选择,最后 POSTROUTING 并发送。我们发现,最后实际上数据报又回到了 Network A,而 Network A 是会把 Packet In 送到 PREROUTING 的。也就是说,只要 OUTPUT 的最后我们的目标恰好是本机的话,那么这份数据报就会重新回到 iptables 的手中,也就和局域网的其他机器所发送的报文一样了。
也就是说,网关发送至网关mangle 表的 OUTPUT 链下手设置 fwmark。只要和上文中一样,将 mark 设置成 1,那么这份数据报就会被作为流入流量重新发送给网关自己,于是问题就迎刃而解了。
结语
iptables 是伟大的存在,TProxy 更是给我们提供了无限的可能性。
TProxy 的核心真的很简单,正是因为它的简单,反而让初见的我不知所措,直到读完源码才明白其真意所在。
写这篇文章之前和写下这篇文章时的探索让我对 Linux 的网络有了更深的了解,真的可以说是收获颇丰。这也是我第一次接触 Linux 内核的某一部分,全文如果出现错误的话还敬请各位斧正。
最后留一个很简单的小问题吧:为什么 TProxy 的网关的最大文件描述符数量要设置地较高呢?如果你对 Linux 的网络有一定了解,或者经由这篇文章对 Linux 的网络有了些许了解的话,相信这个问题的答案已经呼之欲出了。
参考链接
- [1] Abusing Linux’s firewall: the hack that allowed us to build Spectrum - https://blog.cloudflare.com/how-we-built-spectrum/
- [2] xt_TPROXY.c - https://elixir.bootlin.com/linux/v4.16.1/source/net/netfilter/xt_TPROXY.c
- [3] 为什么 TCP 协议有 TIME_WAIT 状态 - https://draveness.me/whys-the-design-tcp-time-wait/
- [4] Transparent proxy support - https://www.kernel.org/doc/Documentation/networking/tproxy.txt
- [5] Linux transparent proxy support - https://powerdns.org/tproxydoc/tproxy.md.html
- [6] Man page of iptables-extensions - http://ipset.netfilter.org/iptables-extensions.man.html
- [7] https://wiki.ubuntu.org.cn/images/f/f0/Iptables.gif
{kind=link}